
DEskriptive Statistik
fmc_Average(Name, Referenz), fmc_Mean(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den Erwartungswert oder auch Mittelwert genannt. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende Zahlen für die Variable "Name" seien vorhanden: 10, 20, 30. Der Mittelwert ergibt sich durch Summenbildung der Zahlen, dividiert durch die Anzahl der Beobachtungen: (10 + 20 + 30) / 3 = 20.
fmc_Variance(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" die Stichprobenvarianz. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende Zahlen für die Variable "Name" seien vorhanden: 10, 20, 30. Der Erwartungswert ist 20. Die Varianz ergibt sich durch die Summe der quadrierten Abweichungen vom Erwartungswert, dividiert durch die Anzahl der Beobachtungen - 1.
Varianz: (10 - 20)^2 + (20-20)^2 + (30-20)^ / (3 -1) = 100.
fmc_StdS(Name, Referenz)
Ermittelt die Stichprobenabweichung der Verteilung "Name", bezugnehmend auf die Variante "Referenz".
Folgende Zahlen für die Variable "Name" seien vorhanden: 10, 20, 30. Der Erwartungswert ist 20. Die Varianz ergibt sich durch die Summe der quadrierten Abweichungen vom Erwartungswert, dividiert durch die Anzahl der Beobachtungen - 1. Die Stichprobenabweichung ist die Wurzel der Varianz.
Varianz: (10 - 20)^2 + (20-20)^2 + (30-20)^ / (3 -1) = 100. Die Standardabweichung der Stichprobe entspricht somit Wurzel(100) = 10.
fmc_Skewness(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" die Schiefe. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Die Schiefe gibt an, ob und wie stark die Verteilung nach rechts (rechtssteil, linksschief, negative Schiefe) oder nach links (linkssteil, rechtsschief, positive Schiefe) geneigt ist.
Folgende Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40. Die Schiefe beträgt 0. Die Semivarianz links vom Mittelwert ist somit gleich gross wie die Semivarianz rechts vom Mittelwert (=20).


fmc_Kurtosis(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" die Kurtosis, oder auch Wölbung. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Die Kurtosis gibt die Spitzigkeit im Vergleich zu der Normalverteilung an. Eine Kurtosis nahe 0 lässt somit auf eine Normalverteilung der betrachteten Zahlen schliessen. Eine Kurtosis kleiner 0 lässt darauf schliessen, dass die Verteilung im Vergleich zur Normalverteilung eher "flachgipflig" ist, eine Kurtosis > 0 ist somit "steiggipflig".
Folgende Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40. Die Kurtosis beträgt -1.88. Die Zahlen verhalten sich im Vergleich zur Normalverteilung somit "flachgiplig", siehe Bild unten (Kurtosis = y).


fmc_Semivariance(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" die Semivarianz der Stichprobe. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Die Semivarianz ermittelt die Varianz für alle Werte einer Simulation, welche unter dem Mittelwert zu liegen kommen.
Folgende Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40. Der Mittelwert beträgt hierbei 20; somit wird die Varianz auf die Zahlen 0, 5, 10 angewandt.
Semivarianz: (0 - 5)^2 + (5-5)^2 + (10-5)^2 / (3-1) = 25
fmc_SemivarianceL(Name, Limit, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" die Semivarianz der Stichprobe, für welche die Wert kleiner als "Limit" sind. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40. Das Limit wird mit 20 angegeben; somit wird die Varianz auf die Zahlen 0, 5, 10 angewandt. Der Mittelwert liegt bei 5.
SemivarianzL: (0 - 5)^2 + (5-5)^2 + (10-5)^2 / (3-1) = 25
fmc_SemivarianceR(Name, Limit, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" die Semivarianz der Stichprobe, für welche die Wert grösser als "Limit" sind. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40. Das Limit wird mit 20 angegeben; somit wird die Varianz auf die Zahlen 30, 35, 40 angewandt. Der Mittelwert liegt bei 35.
SemivarianzR: (30 - 35)^2 + (35-35)^2 + (40-35)^2 / (3-1) = 25
fmc_Percentile(Name, Percentile, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den Wert für "Percentile". Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40, insgesamt 7 Zahlen. "Percentile" wird mit 0.5 angegeben. Das Resultat wird mit Aufrunden(Anzahl Zahlen * Percentile) ermittelt, somit Aufrunden(7 * 0.5) -> Aufrunden(3.5) = 4. Die Zahl an der 4. Stelle wird somit als Resultat zurückgegeben, hier 20.
fmc_PercentileValue(Name, Value, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den Perzentilwert für "Value". Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40, insgesamt 7 Zahlen. "Value" wird mit 20 angegeben. Dieser Wert befindet sich in der 4. Position und somit in der Mitte der genannten Zahlen. Als Resultat wird 0.5 zurückgegeben. Resultate von 0 bis 1 [0%-100%] sind möglich.
Info: Bei stetigen Zahlen wird der Perzentilwert der nächst höheren Zahl zurückgegeben. Bei Angabe von 19.1 wäre der Rückgabewert somit ebenfalls 0.5.
fmc_PercentileInterval(Name, LowerLimit, UpperLimit, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den Perzentilwert welcher zwischen (oder gleich) "LowerLimit" und "UpperLimit" liegt. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40, insgesamt 7 Zahlen. "LowerLimit" wird mit 5 und "UpperLimit" mit 35 angegeben. Die Zahlen 10, 20 und 30 liegen innerhalb dieses Limits. Als Resultat wird 4 / 7 = 0.57 zurückgegeben. Knapp 57% der Zahlen liegen zwischen (und gleich) 5 und 35. Resultate von 0 bis 1 [0%-100%] sind möglich.
fmc_CV(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den Variationskoeffizienten. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Der Variationskoeffizient entspricht dem Verhältnis aus Stichprobenstandardabweichung und dem Erwartungswert.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40, insgesamt 7 Zahlen. Die Stichprobenvarianz beträgt 100, der Erwartungswert 20. Der Variationskoeffizient ist somit 0.5 (Wurzel(100) / 20).
Der Variationskoeffizient ist eine Normierung der Varianz: Ist die Standardabweichung grösser als der Mittelwert bzw. der Erwartungswert, so ist der Variationskoeffizient grösser 1.
fmc_Min(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den kleinsten Wert. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40, insgesamt 7 Zahlen. Der kleinste Wert ist 0.
fmc_Max(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den grössten Wert. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40, insgesamt 7 Zahlen. Der grösste Wert ist 40.
fmc_Mode(Name, Number_bins, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den wahrscheinlichsten Wert auf Basis von "Number_bins" Anzahl Säulen. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 30, 35, 40, insgesamt 8 Zahlen. Die Zahl 30 kommt zweimal vor, alle anderen Zahlen hingegen nur einmal. Der wahrscheinlichste Wert ist somit 30.
Info: Bei stetigen Zahlen werden in einem ersten Schritt alle Zahlen in ein Histogramm mit "Number_bins" Anzahl Säulen überführt und der einfache Mittelwert aus den Grenzen des Histogramms mit den meisten Einträgen als wahrscheinlichster Wert ermittelt.
Im folgenden Histogramm hat Zeile 3 die meisten Einträge (26). Der wahrscheinlichste Wert ist der Durchschnitt der unteren ("Lower") und oberen ("Upper") Grenze der Zeile 3, somit 25.125.

fmc_Sum(Name, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" die Summe. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40, insgesamt 7 Zahlen. Die Summe und somit Resultat ist 140.
fmc_Density(Name, Value, Number_bins, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" die Dichte am Punkt "Value" auf Basis von "Number_bins" Anzahl Säulen. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 30, 35, 40, insgesamt 8 Zahlen. Gesucht ist die Dichte am Wert 30. Die Zahl 30 kommt zweimal vor, daher ist die Dichte 2 / 8 = 0.25.
Bei stetigen Zahlen werden in einem ersten Schritt alle Zahlen in ein Histogramm mit "Number_bins" Anzahl Säulen überführt und diejenigen Zahlen herangezogen welche innerhalb der Grenzen von "Value" liegen. Sei Value 23.1. Diese Zahl wird durch die Grenzen aus Zeile 3 überdeckt, 26 Einträge finden sich hierbei. Insgesamt sind 156 Einträge vorhanden. Die Dichte am Wert 23.1 ergibt sich aus 26/156 = 0.167.

fmc_PosValue(Name, Pos, Referenz)
Ermittelt für die Variable "Name", bezugnehmend auf die Variante "Referenz" den Wert an der Position "Pos". Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende Zahlen für die Variable "Name" seien vorhanden: 12, 3, 10, 20, -5. Die Zahl an Position 3 ist die 10.
Zusammenhangsfunktionen
fmc_Spear(Matrix 1, Maxtrix 2)
Ermittelt für die Zahlenreihe "Matrix 1" und "Matrix 2" den Spearman Rangkorrelationskoeffizienten. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben. Weitere Informationen finden Sie auf Von Korrelationen - Pearson vs. Spearman - Monte-Carlo Simulation leicht gemacht (mcflosim.ch)
fmc_Pearson(Matrix 1, Maxtrix 2)
Ermittelt für die Zahlenreihe "Matrix 1" und "Matrix 2" den linearen Korrelationskoeffizienten gemäss Pearson. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben. Weitere Informationen finden Sie auf Von Korrelationen - Pearson vs. Spearman - Monte-Carlo Simulation leicht gemacht (mcflosim.ch)
Der Pearson Korrelationskoeffizient entspricht der Wurzel des Bestimmtheitsmass (R2) des linearen Regressionsmodells. Das R2 variiert im Regelfall zwischen 0 und 1. Der Korrelationskoeffizient ist daher zwischen -1 (starker negativer linearer) und +1 (starker positiver linearer) definiert. Im Folgenden beträgt das R2 0.7894. Der Korrelationskoeffizient ist daher = Wurzel(0.7894) = 0.885

fmc_FitC(Spalte 1, Spalte 2)
Ermittelt für die Variable "Spalte1" und "Spalte2" das Korrelationsmuster. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben. Weitere Informationen finden Sie auf Von Korrelationen - Pearson vs. Spearman - Monte-Carlo Simulation leicht gemacht (mcflosim.ch). Ergebnis ist eine Zahl von 0-9. Folgend sehen sie mögliche Korrelationsmuster (0 = Normalverteilung, 1 = Clayton Copula).
Folgende Regressionsmuster (Copula) können erkannt werden:
0 - Normal
1 - Clayton
2 - rClayton (inverse Clayton)
3 - Gumbel
4 - rGumbel (inverse Gumbel)
5 - Student-t
6 - asymmetrisch Gumbel
7 - asymmetrisch Dreieck
8 - asymmetrisch Fréchet
Ein Beispiel finden Sie im Referenzbeispiel "MC FLO Test.xlsx" im Reiter "Data".








fmc_CorrRank(Name, Rank, Referenz)
Ermittelt für die Ausgabevariable "Name", bezugnehmend auf die Variante "Referenz" den Pearson Korrelationskoeffizienten der Eingabevariable am Rank k, mit k >= 1. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Beispiel: Im Modell sind fünf Eingangsvariablen mit folgenden (absolut absteigend sortierten) Pearson-Korrelationskoeffizienten von -0.9, 0.7, -0.65, 0.5, 0.3 in Bezug auf die Ausgangsvariable "Name" vorhanden. Mit Rank = 3 wird die dritt höchste Grösse (hier -0.65) ausgegeben.
fmc_CorrRankN(Name, Rank, Referenz)
Ermittelt für die Ausgabevariable "Name", bezugnehmend auf die Variante "Referenz" den Namen der Variablen mit dem Pearson Korrelationskoeffizienten am Rank k, mit k >= 1. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Beispiel: Im Modell sind fünf Eingangsvariablen mit folgenden (absolut absteigend sortierten) Pearson-Korrelationskoeffizienten von -0.9 [V1], 0.7 [V2], -0.65 [V3], 0.5 [V4], 0.3 [V5] (in Klammern die Namen) in Bezug auf die Ausgangsvariable "Name" vorhanden. Mit Rank = 3 wird der Name der dritt höchste Grösse (hier V3) ausgegeben.
fmc_CorrS(Name1, Name2, Referenz)
Ermittelt für die Variablen "Name 1" und "Name 2" bezugnehmend auf die Variante "Referenz" den Spearman Rangkorrelationskoeffizienten. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben. Weitere Informationen finden Sie auf Von Korrelationen - Pearson vs. Spearman - Monte-Carlo Simulation leicht gemacht (mcflosim.ch)
fmc_CorrP(Name1, Name2, Referenz)
Ermittelt für die Variablen "Name 1" und "Name 2" bezugnehmend auf die Variante "Referenz" den Pearson Korrelationskoeffizienten. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben. Weitere Informationen finden Sie auf Von Korrelationen - Pearson vs. Spearman - Monte-Carlo Simulation leicht gemacht (mcflosim.ch)
fmc_Spider(Name1, Name2, Value1, Value2, Referenz)
Errechnet den linearen Korrelationskoeffizienten (Pearson) zwischen den Datenpunkten "Value1" und "Value2" der Variable 1 "Name1" mit den entsprechenden Daten der Variable 2 "Name2". Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Für Variable 1 sollen für alle Zahlen gleich oder grösser 10 und kleiner 35 mit den entsprechenden Werten von Variable 2 der linearen Korrelationskoeffizient ermittelt werden. Das Ergebnis ist 0.87.

fmc_DSensitivity(Name1, Name2, DSensotype, Number_bins, Referenz)
Berechnet die dynamische Sensitivität zwischen zwei Variablen «Name1» und «Name2»; «DSensotype» gibt an, welcher Wert ausgegeben werden soll, die ; 0 = Bandbreite; 1 = Minimum; 2 = Maximum. «Number_bins» gibt die Anzahl Säulen des zugrunde liegenden Histogramms an. Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Die dynamische Sensitivität drückt aus, ob die Werte von «Name2» stark um «Name1» schwanken. Hierzu werden in einem ersten Schritt alle Werte von Name1 aufsteigend sortiert und in Number_bin gleich Anteile unterteilt. Für jeden Anteil werden die zugehörigen Werte von Name2 ausgewertet, dabei wird die Summe geteilt durch die Anzahl Werte je Anteil als Zwischenwert abgelegt. Die Minima und Maxima der Zwischenwerte über alle Anteile werden dann für das Ergebnis herangezogen.
Im Beispiel ist Number_bin = 2; Name1 wurde in Intervalle von 0-10 und 10 bis 21 unterteilt, wobei 0 das Minimum und 21 die Maximum von Name1 ist. Für Name1 fallen für Zahlen von 0-10 folgende Zahlen bei Name2 an: 3,4,5,14. Die Bandbreite ist 11 (14-3). Für den zweiten Anteil ist die Bandbreite 8. Folgende mögliche Resultate resultieren
DSensotype = 19/2 = 9.5 (Bandbreite, Durchschnitt aus Summe von 11 und 8)
DSensotype = 1 (Min): 6.5 (Minimum der Durchschnitts)
DSonsotype = 2 (Max): 7.7 (Maximum des Durchschnitts)
Maximal korrelierte Variablen haben eine Bandbreite nahe der durch "Lower" und "Upper" vorgegebenen Intervalle.

Portfolio / Finanzfunktionen
fmc_ExtremeValue(Name1, Pos, Referenz)
Gibt den Wert an der i-ten Position der aufsteigend sortierten Liste der Variable Name1 wieder, bezugnehmend auf die Variante "Referenz" . Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: 0, 5, 10, 20, 30, 35, 40, insgesamt 7 Zahlen. Mit Pos = 6 wird die Zahl 35 als Ergebnis zurückgegeben.
fmc_ExpGain(Name1, Referenz)
Berechnet den Mittelwert der Werte der Verteilung «Name1», die über den Schwellenwert von 0 liegen, bezugnehmend auf die Variante "Referenz". Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: -5, 0, 5, 10, 20, 30, 35, 40, insgesamt 8 Zahlen. Der Mittelwert aller positiven Zahlen und somit Ausgabeergebnis ist 23.33
fmc_ExpGainV(Name1, Referenz)
Berechnet die Varianz der Werte der Verteilung «Name1», die über den Schwellenwert von 0 liegen, bezugnehmend auf die Variante "Referenz". Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: -5, 0, 5, 10, 20, 30, 35, 40, insgesamt 8 Zahlen. Die Varianz aller positiven Zahlen und somit Ausgabeergebnis ist 187.5.
fmc_ExpLoss(Name1, Referenz)
Berechnet den Mittelwert der Werte der Verteilung «Name1», die unter den Schwellenwert von 0 liegen, bezugnehmend auf die Variante "Referenz". Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: -10, -5, 0, 5, 10, 20, 30, 35, 40, insgesamt 9 Zahlen. Der Mittelwert aller negativen Zahlen und somit Ausgabeergebnis ist -7.5.
fmc_ExpectedShortfall(Name1, Percentile, Referenz)
Berechnet den Expected Shortfall oder auch Conditional-Value-at-risk der Verteilung «Name» bei der Value-at-risk Position «Percentile», bezugnehmend auf die Variante "Referenz". Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende (aufsteigend sortierte) Zahlen für die Variable "Name" seien vorhanden: -20, -10, -5, 0, 5, 10, 20, 30, 35, 40, insgesamt 10 Zahlen. Percentile ist mit 0.2 angegeben, somit werden die ersten zwei Zahlen (0.2 * 10), also -20 und -10 betrachtet. Das Ergebnis ergibt sich aus dem Mittelwert und lautet -15.
Beachten Sie, dass eine Differenzierung nach Perzentilen vorgenommen wird: Ist das Perzentil unter 0.5 werden alle Werte links davon herangezogen, sonst alle Werte rechts davon.
Um negative und positive Werte zu differenzieren, empfehlen wir Ihnen, dass Sie die Funktion fmc_BayesV nutzen.
fmc_BSMVal(Basis, Time, Interest, Sigma)
Gibt den Preis eines Titel nach «Time» Handelstagen gemäss dem Black-Scholes-Merton Modell an, dies ausgehend vom «Basis» Preis, dem risikolosen Zinssatz «Interest» und der konstanten Volatilität «Sigma».
fmc_FinancialDTrans(Initial, Periods, ActualYear, Amount)
Ermittelt auf Basis des Anfangsdatums («Initial») und der Dauer («Periods») den proportionalen Anteil pro Jahr (über «Actual Year») des Betrages «Amount».
Folgendes Beispiel (=fMC_FinancialDTrans($C$27;$C$29;C30;$C$28/$C$29)): In Zelle C27 ist das Startdatum 01.11.2024 hinterlegt, etwa den Beginn der Abschreibung, Es wird über 5 Jahre (C29) der Betrag von 5000 (C28) aufgeteilt. Die Jahre (C30ff.) sind in Spalten abgetragen, für ein ganzes Jahr ist der Betrag C28/C29 (5000/5=1000) anzusetzen. Für das erste Jahr (Monate Nov-Dezember) werden 1634.38, im Jahr 2029 wird der noch ausstehende Betrag von 836.62 "abgeschrieben".

fmc_FinancialValue(Name1, Name2, Value2, Diff, Value1, Referenz)
Berechnet die Ausprägung des Ereignis A (Name1), gegeben das Ereignis B (Name2) eingetroffen ist, bezugnehmend auf die Variante "Referenz". Für das Ereignis B enthält der Suchraum +/-% der unter Diff eingegebenen Grenze. Resultat ist das Perzentil «Value1» von «Name1».
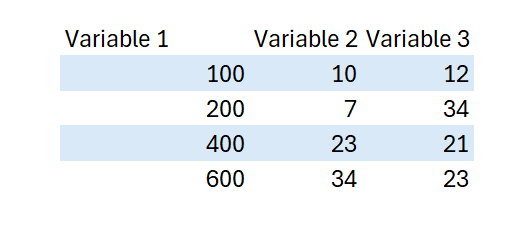
Folgende Zahlen liegen vor:

Für Variable 1 (Name1) soll der Durchschnitt ermittelt werden, falls Variable 2 (Name2) den Wert von 4 mit einer Abweichung von +/- 50% annimmt -> fmc(FinancialValue(Name1, Name2, 4, 0.5). In diesem Fall werden alle Werte von Variable 2 berücksichtigt, welche zwischen 2 und 6 liegen. Für die Variable 1 ergeben sich somit die Werte 5, 10 und 20. Der Durchschnitt davon und somit das Ergebnis ist 35/3.
Info: Beachten Sie, dass Sie das Ergebnis ebenfalls mit Funktionen aus der Bayesschen Statistik reproduzieren können.
fmc_ConditionalPosValue(Name1, Value, Referenz)
Gibt die Position der Liste von «Name1» zurück, welcher mit dem angegebenen Wert «Value» übereinstimmt, bezugnehmend auf die Variante "Referenz".
Folgende Werte für die Variable "Name" sind vorhanden / wurden simuliert: -3, 2, 4.5, 3.1. Mit Value wird 4.5 angegeben, Rückgabewert ist die Position bei Value, hier 3.
fMC_PortfolioCombn(Value)
Bestimmt die Anzahl Kombinationen (ohne Wiederholung, ohne bestimmte Reihenfolge) von n («Value») Titeln eines Portfolios.
Beispiel: Es sind 10 Projekte verfügbar, es ergeben sich somit 1'023 von der leeren Menge abweichende mögliche Kombinationen ein Portfolio zusammenzustellen. Es ist zu berücksichtigen, dass selbst die Durchführung nur eines Projektes ein Portfolio darstellt.
Details können Sie der mit MC FLO mitgelieferten Beispieldatei "Portfolio_Markowitz.xlsx" entnehmen.
fMC_PortfolioMatrix(aMatrix, AsInput, Comparex, Comparesx, Comparevx)
Bestimmt die Möglichkeiten zur Bildung eines Portfolios mittels Matrixfunktion, bei der n Titel ausgewählt werden. Ausgabe ist eine n x 2 Matrix, bei der die erste Spalte die berechneten MC FLO Variablen und die zweite Spalte die Namen enthält. Falls AsInput = WAHR (1), dann werden die berechneten MC FLO Variablen als Inputvariablen hinterlegt, ansonsten als Outputvariablen. Es werden bis zu 5 Nebenbedingungen als Matrix («Comparex»), mit Vergleichsparameter «Comparesx» und Referenzwert «Comparevx» unterstützt.
Weitere Informationen finden Sie unter: Quantitatives Portfoliomanagement - Teil II - Monte-Carlo Simulation leicht gemacht (mcflosim.ch).
Details können Sie der mit MC FLO mitgelieferten Beispieldatei "Portfolio_Markowitz.xlsx" entnehmen.
fMC_PortfolioCorrMatrix(aMatrix, FillRandom)
Bestimmt die Korrelationsmatrix eines Portfolios aus n Titeln. Resultat ist eine q x 1 Matrix. Falls «FillRandom» = WAHR (1), dann wird jede Korrelationsbeziehung mit einem zufälligen Wert zwischen -0.3 und +0.3 hinterlegt, andernfalls mit dem Wert 0.
Weitere Informationen finden Sie unter: Quantitatives Portfoliomanagement - Teil II - Monte-Carlo Simulation leicht gemacht (mcflosim.ch)
Details können Sie der mit MC FLO mitgelieferten Beispieldatei "Portfolio_Markowitz.xlsx" entnehmen.
fMC_PortfolioCorrMatrixF(aMatrix, CorrelT)
Bestimmt alle Korrelationskombinationen und deren Korrelationskoeffizienten aus n Variablen aus «aMatrix». Resultat ist eine Matrix mit n x (n-1) / 2 Zeilen; «CorrelT»: Bestimmt den Korrelationskoeffizienten: 0 = Pearson, ansonsten Spearman.
Weitere Informationen finden Sie unter: Quantitatives Portfoliomanagement - Teil II - Monte-Carlo Simulation leicht gemacht (mcflosim.ch).
Details können Sie der mit MC FLO mitgelieferten Beispieldatei "Portfolio_Markowitz.xlsx" entnehmen.
fMC_PortfolioManualMatrix(aMatrix, cMatrix, isInput)
Ermittelt ein Portfolio auf Basis einer 0-1 Matrix. Objekte mit einer 1 werden in das Portfolio aufgenommen. Dabei entspricht aMatrix den Bezeichnungen der Titel (als nx1 Matrix), aus der das Portfolio bestimmt wird und cMatrix ist eine nxm Matrix mit 0-1 Zahlen. Achten Sie darauf, dass die Anzahl Zeilen (n) mit der Anzahl Zeilen der Eingangsmatrix übereinstimmt. Falls isInput = WAHR (1), dann werden die berechneten MC FLO Variablen als Inputvariablen hinterlegt, ansonsten als Outputvariablen.
Weitere Informationen finden Sie unter: Quantitatives Portfoliomanagement - Teil II - Monte-Carlo Simulation leicht gemacht (mcflosim.ch).
Details können Sie der mit MC FLO mitgelieferten Beispieldatei "Portfolio_Markowitz.xlsx" entnehmen.
fMC_SimpleMarkovChain(aMatrix, n)
Modell einer Markow Kette, zur Bestimmung eines Endzustands nach «n» Perioden. Ausgangslage ist eine n x m Matrix. Ausgabe ist ebenfalls eine n x m Matrix.
Ein vollständiges Beispiel ist in Markov-Chain.xlsx enthalten.
Parameterfreie Statistik
fmc_Kernel(Name, AdaptRate, Number_bins, Bandwith, ReturnHistogram)
Führt eine automatische Kerndichteschätzung für die Variable «Name» durch, dies auf Basis eines Gauss-Kerns. Resultat ist eine Matrix mit nx1 Einträgen (falls ReturnHistogram = 0) oder mit «Number_bins» x 3 Einträgen (falls ReturnHistogram = 1). «Bandwith» entspricht der Bandbreite und «Number_bins» entspricht der Anzahl Säulen des Histogramms und «AdaptRate» der Anpassungsrate (in %). Sie gibt an, um wieviel % der kleinste Wert nach unten und der höchste Wert für die Kerndichteschätzung nach oben angepasst werden soll.
Info: Ohne Angabe von «Bandwith» wird diese automatisch hergeleitet.
Weiterführende Informationen finden Sie in der Beispieldatei "Kernel_estimation.xlsx"

fMC_Kernel2(Data, LowerLimit, UpperLimit, Bandwith, Number_bins)
Führt eine Kerndichteschätzung für die in Excel ausgewählten Daten durch, dies auf Basis eines Gauss-Kerns. Resultat ist nx1 Matrix (falls ReturnSample = WAHR, mit n = Sample) oder eine nx3 Matrix (falls ReturnHistogram = WAHR) wobei n der Anzahl Klassen («Number_bins») des Histogramms entspricht. «LowerLimit» und «UpperLimit» geben die Bereichsgrenzen an, «Bandwith» die Bandbreite und «Number_bins» die Anzahl der auszugebenen Säulen des Histogramms.
Weiterführende Informationen finden Sie in der Beispieldatei "Kernel_estimation.xlsx".

fMC_BootStrap(Matrix1, NumIt, Confidence, Percentile)
Markiert die unter Matrix1 ausgewählte Spalte oder Zeile als Stichprobe und bestimmt das Konfidenzintervall (Confidence) des Mittelwertes dieser Stichprobe unter Zuhilfenahme von NumIt neuer Stichproben (Ziehen mit Zurücklegen). Resultat ist ein String mit (Mittelwert, unterer Bereich, oberer Bereich). Wird Percentile angegeben, wird das Konfidenzintervall des entsprechenden Perzentils statt des Mittelwertes ausgewiesen.
Weitere Informationen finden Sie unter: Bootstrap
fMC_BootStrapN(Name, NumIt, Confidence, Percentile)
Markiert die unter Name angegebene Variable einer Simulation als Stichprobe und bestimmt das Konfidenzintervall (Confidence) des Mittelwertes dieser Stichprobe unter Zuhilfenahme von NumIt neuer Stichproben (Ziehen mit Zurücklegen). Resultat ist ein String mit (Mittelwert, unterer Bereich, oberer Bereich). Wird Percentile angegeben, wird das Konfidenzintervalls des entsprechenden Perzentils statt des Mittelwertes ausgewiesen.
Weitere Informationen finden Sie unter: Bootstrap
fMC_BootStrapVector(Matrix1, NumNewExamples, Percentile, ReturnPercentH, Compound)
Markiert die unter Matrix1 ausgewählte Spalte oder Zeile als Stichprobe und bestimmt unter Zuhilfenahme von NumNewExamples entsprechend neue Stichproben (Ziehen mit Zurücklegen). Wird Percentile angegeben, wird das entsprechende Perzentil der jeweiligen Stichprobe ausgewiesen, andernfalls der Mittelwert. Ausgabe ist eine nx1 Matrix, wobei n = NumNewExamples entspricht. Falls die Ausgangsdaten aus einer Bernoulli Verteilung stammen, kann mit ReturnPercentH der entsprechende %-Wert der Treffer (=1) ermittelt werden. Wird Compound mit > 1 angegeben, wird die Summe von Anzahl Compound gebildet.
Beispiel: Sie haben die Zahlen 3, 12, 7: Es soll eine neue Möglichkeit (NumNewExamples = 1) ausgegeben werden.
Ohne Auswahl von "Percentile" wird der Mittelwert ausgegeben, hier 10, bestehend aus der neuen Möglichkeit 12, 12 und 3.
Beispiel: Sie haben die Zahlen 3, 12, 7: Es soll eine neue Möglichkeit (NumNewExamples = 1) ausgegeben werden, mit Compound = 2. Es wird die Zahl 10 ausgegeben. Diese setzt sich aus der Summe 3 + 7 zusammen; beide Zahlen wurden zufällig ausgewählt.
Beachten Sie, dass wenn ganze Zahlen eingegeben werden, auch ganze Zahlen (gerundet) zurückgegeben werden. Möchten Sie nicht ganzzahlige Zahlen als Rückgabe haben, ist mindestens eine Zahl leicht anzupassen. Beispiel: Sie haben die Zahlen 3.00001, 12, 7: Es soll eine neue Möglichkeit (NumNewExamples = 1) ausgegeben werden.
Ohne Auswahl von "Percentile" wird der Mittelwert ausgegeben, hier 4.3, bestehend aus der neuen Möglichkeit 7, 3.00001 und 3.000001.
Weitere Informationen finden Sie unter: Bootstrap
GEnerative, BAYESSCHE Statistik
fMC_BayesCombine(NumberX, ShareX, ReturnData, Number_bins, Referenz)
Kombiniert bis zu fünf (X=1…5) verschiedene A-priori Wahrscheinlichkeitsverteilungen zu einer aggregierten A-priori Verteilung, dies bezugnehmend auf die Variante "Referenz". ReturnData: Gibt an, ob die Daten der kombinierten Verteilung direkt als nx1 Matrix (WAHR) oder als nx3 Histogramm (FALSCH) ausgegeben werden sollen. Falls als Histogramm, dann wird über Number_bin die Anzahl Säulen verwendet.
Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Weiterführende Informationen finden Sie in der Beispieldatei "Subject_Matter_Experts.xlsx".
Die Funktion kann auch als "Selbstreflektion" einer Variablen genutzt werden: fmc_BayesCombine(A1, A1) gibt das Simulationsergebnis der Variable mit dem unter A1 hinterlegtem Variablennamen wieder.
fMC_Bayes(Name1, Vergleich1, Wert1, Name2, Vergleich, Wert2, Referenz)
Berechnet die bedingte Wahrscheinlichkeit für das Ereignis A (Name1), gegeben dass das Ereignis B (Name2) eingetroffen ist, dies bezugnehmend auf die Variante "Referenz". Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Beispiel: fmc_Bayes(‘NPV’;’>=’;1000;’Projektkosten’;’>=’;100) errechnet die Wahrscheinlichkeit, dass NPV grösser gleich als 1000 ist, gegeben, dass die Projektkosten grösser gleich 100 ausfallen. NPV und Projektkosten sind Variablennamen.
fMC_Bayes4(Name1, Vergleich1, Wert1, Name2, Vergleich, Wert2, Name3, Vergleich3, Wert3, Name4, Vergleich4, Wert4, Name5, Vergleich5, Wert5, Referenz)
Berechnet die Wahrscheinlichkeit für das Ereignis A (Name1), gegeben dass Ereignis B, C, D bis E (Name2, Name3, Name4, Name5) eingetroffen ist, dies bezugnehmend auf die Variante "Referenz". Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgendes Beispiel: Wie hoch die Wahrscheinlichkeit, dass Variable 1 >= 100 ist, gegeben dass die Variable 2 grösser gleich 9 und Variable 3 <= 25 ist? Formal somit fmc_Bayes4(Variable 1;">="&100;Variable 2;">="&9;Variable 3;"<="&25).
In zwei Fällen nehmen Variable 2 und Variable 3 die geforderten Werte an (blau) hinterlegt. In diesen zwei Fällen ist die Ausprägung der Variable 1 gleich 100 und 400, beide Werte erfüllen die Bedingung für Variable 1. Das Ergebnis ist somit 1 (100%).

fMC_BayesV(Name1, Vergleich1, Wert1, Name2, Vergleich, Wert2, Referenz)
Berechnet den Durchschnitt des Ereignisses A (Name1), gegeben dass Ereignis B (Name2, eingetroffen ist, dies bezugnehmend auf die Variante "Referenz". Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Beispiel: Sie haben eine Simulation mit den Variablen "EBIT" und "Nachfrage" erstellt. Mit der Formel fmc_BayesV(EBIT; "<=";0;"Name";"<=";500) werden in einem ersten Schritte alle Simulationsergebnisse nach "Name" mit dessen Ausprägung unter/gleich 500 gefiltert. Anschliessend werden auf dieser Teilmenge alle Ergebnisse gefiltert, bei denen der EBIT kleiner/gleich 0 ist. Der Durchschnitt vom resultierenden EBIT wird als Ergebnis ausgegeben.
fMC_Bayes4V(Name1, Vergleich1, Wert1, Name2, Vergleich, Wert2, Name3, Vergleich3, Wert3, Name4, Vergleich4, Wert4, Name5, Vergleich5, Wert5, Referenz)
Berechnet den Durchschnitt das Ereignisses A (Name1), gegeben dass Ereignis B, C, D bis E (Name2, Name3, Name4, Name5) eingetroffen ist, dies bezugnehmend auf die Variante "Referenz". Das Ergebnis wird nach Simulationsdurchlauf angezeigt. Ohne Durchlauf einer Simulation wird eine entsprechende Meldung ausgegeben.
Folgende Daten seien gegeben: Wie hoch ist der durchschnittliche Wert von Variable 1, wenn dieser >= 100 ist, gegeben dass die Variable 2 grösser gleich 9 und Variable 3 <= 25 ist? Formal somit fmc_Bayes4(Variable 1;">="&100;Variable 2;">="&9;Variable 3;"<="&25).
In zwei Fällen nehmen Variable 2 und Variable 3 die geforderten Werte an (blau) hinterlegt. In diesen zwei Fällen ist die Ausprägung der Variable 1 gleich 100 und 400, beide Werte erfüllen die Bedingung für Variable 1. Das Ergebnis ist 250 (100 + 400 = 500, dividiert durch zwei Beobachtungen ergibt 250).
fMC_BayesFactor(ExpectedProbability, ObservedProbability, NumberOfAttempts, NumNewSample, Percentile, Attempts)
Ermittelt den Bayes-Faktor, der das Verhältnis zweier konkurrierender statistischer Annahmen (Nullhypothese gegenüber Alternativhypothese) oder Modelle angibt und so eine Entscheidung über die Verwendung von Annahmen/Modellen ermöglicht. Ein Bayes-Faktor von über 3 als Resultat ist gemäss gängiger Praxis eine glaubwürdige Darstellung, dass die Nullhypothese gegenüber der Alternativhypothese zu bevorzugen ist. Ausgehend von «ExpectedProbability» welche der erwarteten Wahrscheinlichkeit unter der Nullhypothese entspricht, der «ObservedProbability», der gemessenen Wahrscheinlichkeit und Anzahl Versuche («NumberOfAttempts») in einem Binomialmodell wird die gemessene Evidenz der Nullhypothese gegenüber der Alternativhypothese gemessen. Mit «Percentile» kann der Wert des gesuchten glaubwürdigen Intervalls spezifiziert werden; «Attempts» gibt an, wie viele unabhängige Versuche unternommen werden müssen. Details zum Bayes-Faktor sind auf Bayes-Faktor ersichtlich.
fMC_BayesMCMC(Name1, Name2, BurnIn, Thinning, NumberIterations, ReturnData, Number_bins, Number_binsDivide, Referenz)
Kombiniert die A-priori Wahrscheinlichkeitsverteilung (Name1) mit neuen gleichartigen Daten (Likelihood, Name2) zu der A-posteriori Verteilung über das Markov-Chain Monte-Carlo Verfahren (MCMC), dies bezugnehmend auf die Variante "Referenz". «Number_binsDivide» entspricht der Anzahl Säulen des Histogramms, welche zur Bestimmung A-posteriori Verteilung herangezogen wird; «BurnIn» entspricht Anzahl Anfangstreffer, welche nicht in der Ausgabematrix berücksichtigt werden (burn in rate); «Thinning» gibt an, ob jeder (=1) zulässiger Treffer oder nur jeder x-Treffer (> 1) berücksichtigt werden soll. Mit «NumberIterations» wird die Stichprobengrösse der Zielverteilung vorgegeben. «ReturnData» gibt an, ob die Daten der Zielverteilung (a-posteriori Verteilung) direkt als nx1 Matrix (WAHR) oder als nx3 Histogramm (FALSCH) ausgegeben werden sollen. Falls als Histogramm, dann wird über Number_bins die Anzahl Säulen verwendet. Als «Vorschlag» (proposal distribution) wird eine Normalverteilung (Gauβ) beigezogen.
Analog kann die Funktion fMC_BayesMCMCA(«») verwendet werden. In diesem Fall wird eine asymmetrische Gleichverteilung als «Vorschlag» (proposal distribution) genommen.
Weitere Informationen zum Einsatz von MCMC finden Sie im folgenden Blogbeitrag.
MCMC basiert auf den Satz von Bayes. Folgend das Resultat aus der Kombination einer Priori Verteilung (Prior_0) und den gemessenen Daten (Data_1). Das Resultat (Posterior_2) ist eine gewichtete Schnittmengen zwischen Priori und den gemessenen Daten.
Info: Falls die Funktion mit V endet (fmc_MCMCV oder fmc_MCMCAV), wird die Berechnung in Microsoft Excel mit jeder Änderung einer Zelle angestossen.
Info: Falls die Funktion mit der Bezeichnung Vector anschliesst (etwa fmc_MCMCVectorV), werden nicht Namen eines Simulationsmodells als Inputvariablen übergeben, sondern ein Datenvektor.
Im Fall, dass beider Verteilungen nicht schnell konvergieren, können Sie auch fmc_MCMCV_Robust wählen, hier werden Data1, und Data2 als Stichproben der jeweiligen Prior und Likelihood übergeben.

fMC_BayesPrediction(Name1, Name2, Count, NumberIterations, Attempts, ReturnData, Number_bins, Referenz)
Ermittelt eine Prognose auf Basis der A-posteriori Verteilung («Name1») und der entsprechenden Likelihood («Name2»), dies bezugnehmend auf die Variante "Referenz". «Count» entspricht der Anzahl Vorkommnisse, «Attempts» der Anzahl tolerierbaren Fehlversuche. Mit «NumberIterations» wird die Stichprobengrösse der Zielverteilung vorgegeben. «ReturnData» gibt an, ob die Daten der Zielverteilung (Prognoseverteilung) direkt als nx1 Matrix (WAHR) oder als nx3 Histogramm (FALSCH) ausgegeben werden sollen. Falls als Histogramm, dann wird über Number_bins die Anzahl Säulen verwendet
fMC_BayesPredictionRegression(DataY, DataX, Value, Optional Percentile, Optional UseLogForY, Optional UseRepeatedMedianRegression, Optional NumNewSample, Optional kfolds)
Ermittelt eine Prognose für die abhängige Variable (y), gegeben den Wert „Value“ der unabhängigen Variablen (x) anhand eines linearen Bayesschen Regressionsmodells und auf Basis der Daten „DataY“ für die abhängige Variable und „DataX“ für die unabhängige Variable. Mit „Percentile“ geben Sie das gesuchte Perzentil der resultierenden Verteilung, welche die Prognose umfasst, an (ohne Angabe wird der Mittelwert ausgegeben), wobei die Anzahl „NumNewSample“ zur Generierung der Prognoseverteilung herangezogen wird. Bei Auswahl von „UseLogForY“ = 1 (standardmässig = 0) werden die Daten aus „DataY“ logarithmiert in die Berechnung übernommen. Mittels „UseRepeatedMedianRegression“ geben Sie, ob der Kleinst-Quadrate Schätzer (standardmässig = 0) oder die absoluten Abweichungen (bei „UseRepeatedMedianRegression“ = 1) anhand des Median (0.5 Quantil) Schätzers angewandt wird. Mit „kfolds“ (standardmässig = 1) geben Sie an, wie viele unabhängige Stichproben aus der Datenmenge „DataY“ und „DataX“ (paarweise) gewählt werden, um die Stichprobenvariabilität einzugrenzen. Info: Im Fall, dass DataX mehrere Spalten umfasst (multiple, lineare Regression) wird der Kleinst-Quadrate Schätzer genommen.
Bemerkung: Zur Bestimmung der „a-priori“ Verteilung der Regressionsparameter (etwa Steigung, Achsenabschnitt) wird anhand einer Stichprobe von „DataY“ und „DataX“ (paarweise) eine Kerndichteschätzung vorgenommen, um das Regressionsmodell zu stabilisieren. Die Likelihood und deren Verteilung wird anhand des Bootstrap-Verfahrens hergeleitet und mittels Kerndichteschätzer aufbereitet.
fMC_BayesPredictionRegressionParameters(DataY, DataX, CI, Optional FeatureDescription, Optional UseLogForY, Optional UseRepeatedMedianRegression, Optional NumNewSample, Optional kfolds)
Ermittelt die Regressionsparameter anhand eines linearen Bayesschen Regressionsmodells und auf Basis der Daten „DataY“ für die abhängige Variable und „DataX“ für die unabhängige Variable. Mit „CI“ geben Sie das glaubhafte Intervall der resultierenden Verteilung an, wobei die Anzahl „NumNewSample“ zur Generierung der Prognoseverteilung herangezogen wird. Bei Auswahl von „UseLogForY“ = 1 (standardmässig = 0) werden die Daten aus „DataY“ logarithmiert in die Berechnung übernommen. Mittels „UseRepeatedMedianRegression“ geben Sie, ob der Kleinst-Quadrate Schätzer (standardmässig = 0) oder die absoluten Abweichungen (bei „UseRepeatedMedianRegression“ = 1) anhand des Median (0.5 Quantil) Schätzers angewandt wird. Mit „kfolds“ (standardmässig = 1) geben Sie an, wie viele unabhängige Stichproben aus der Datenmenge „DataY“ und „DataX“ (paarweise) gewählt werden, um die Stichprobenvariabilität einzugrenzen. „FeatureDescription“ geben die Bezeichnungen von „DataX“ an. Resultat ist eine (m + 2) x 4 Matrix, wobei m die Anzahl der unabhängigen Variablen umfasst, zuzüglich einer Zeile für den Schnittpunkt und eine Zeile für den Regressionsfehler der Regressionsgleichung.
Info: Im Fall, dass DataX mehrere Spalten umfasst (multiple, lineare Regression) wird der Kleinst-Quadrate Schätzer genommen.
fMC_BayesPredictionRegressionCIP(TrainDataY, TrainDataX, TestDataY, TestDataX, Optional Percentile, Optional UseLogForY, Optional UseRepeatedMedianRegression, Optional NumNewSample, Optional kfolds)
Ermittelt die Überdeckungsrate neu gemessener Daten „TestDataY“ und „TestDataX“ anhand eines Bayesschen linearen Regressionsmodells, basierend auf den Trainingsdaten „TrainDataY“ und „TrainDataX“. Mit „Percentile“ geben Sie den gesuchten Deckungsbereich an, mit der die Überdeckungsrate ermittelt wird (ohne Angabe wird das 95%-Perzentil herangezogen).
Bei Auswahl von „UseLogForY“ = 1 (standardmässig = 0) werden die Daten aus „TrainDataY“ logarithmiert in die Berechnung übernommen. Mittels „UseRepeatedMedianRegression“ geben Sie, ob der Kleinst-Quadrate Schätzer (standardmässig = 0) oder die absoluten Abweichungen (bei „UseRepeatedMedianRegression“ = 1) anhand des Median (0.5 Quantil) Schätzers angewandt wird. Mit „kfolds“ (standardmässig = 1) geben Sie an, wie viele unabhängige Stichproben aus der Datenmenge „DataY“ und „DataX“ (paarweise) gewählt werden, um die Stichprobenvariabilität einzugrenzen. Info: Im Fall, dass DataX mehrere Spalten umfasst (multiple, lineare Regression) wird der Kleinst-Quadrate Schätzer genommen.
Interpretation: Sie lassen ein Modell mit Perzentil 95% auf 100 Testdaten verproben. Als Resultat wird eine 1 (100%) ausgegeben; d.h, dass in diesem Fall das Modell von 100 Testdaten 95 richtig innerhalb des Prognoseintervalls identifiziert hat, 5 Testfälle fallen ausserhalb der jeweiligen Prognoseintervalls. Resultat ist somit 95 (richtig erkannt) / 95 (%-Perzentil) = 1. Würden hingegen von 100 Testdaten alle innerhalb des jeweiligen Prognoseintervalls fallen, wäre das Ergebnis 100 / 0.95 1.05 (105%). Werden bei einem Perzentil von 50% von 100 Testdaten, 50 richtig erkannt, resultiert hier eine Überdeckungsrate von 1 (100%; 50 (richtig erkannt) / 50 (%-Perzenzil)). Ein gutes Modell sollte eine Überdeckungsrate von nahe 100% im jeweiligen Perzentil aufweisen. Überdeckungsraten von unter 100% deuten darauf hin, dass die anhand der Trainingsmenge ermittelten Regressionsparamater die Testdaten nicht korrekt antizipieren. Dies ist bei steigender Dispersion der Daten beobachtbar. Bei Überdeckungsraten von über 100% ist a-priori von sinkender Dispersion gegenüber den Trainingsdaten auszugehen.
fMC_BayesPredictionRegressionMAE(TrainDataY, TrainDataX, TestDataY, TestDataX, Optional Percentile, Optional UseLogForY, Optional UseRepeatedMedianRegression, Optional NumNewSample, Optional kfolds)
Ermittelt den durchschnittlichen, absoluten Fehler neu gemessener Daten „TestDataY“ und „TestDataX“ anhand eines Bayesschen linearen Regressionsmodells, basierend auf den Trainingsdaten „TrainDataY“ und „TrainDataX“.
Bei Auswahl von „UseLogForY“ = 1 (standardmässig = 0) werden die Daten aus „TrainDataY“ logarithmiert in die Berechnung übernommen. Mittels „UseRepeatedMedianRegression“ geben Sie, ob der Kleinst-Quadrate Schätzer (standardmässig = 0) oder die absoluten Abweichungen (bei „UseRepeatedMedianRegression“ = 1) anhand des Median (0.5 Quantil) Schätzers angewandt wird. Mit „kfolds“ (standardmässig = 1) geben Sie an, wie viele unabhängige Stichproben aus der Datenmenge „DataY“ und „DataX“ (paarweise) gewählt werden, um die Stichprobenvariabilität einzugrenzen. Info: Im Fall, dass DataX mehrere Spalten umfasst (multiple, lineare Regression) wird der Kleinst-Quadrate Schätzer genommen.
Interpretation: Das Regressionsmodell, respektive die Regressionsgerade sollte im Erwartungswert möglichst „gute“ Prognosen ermöglichen. Je grösser der prognostizierte Wert vom tatsächlichen Wert anhand der Testdaten abweicht, desto grösser der Standardfehler und somit der mittlerer absolute Fehler. Ein Grund kann sein, dass die Modellspezifikation von der tatsächlichen bedingten Verteilung abweicht, oder das Regressionsmodell von vielen weiteren, nicht im Modell berücksichtige Variablen abhängt. Ein grosser Standardfehler führt wiederrum dazu, dass das glaubwürdige Intervall für einen Punktschätzer sehr breit wird und daher das Regressionsmodell als Prognosemodell ungeeigneter wird
fMC_BayesPredictionRegressionResiduals(TrainDataY, TrainDataX, TestDataY, TestDataX, Optional Percentile, Optional UseLogForY, Optional UseRepeatedMedianRegression, Optional NumNewSample, Optional kfolds)
Ermittelt die Residuen (Fehler) neu gemessener Daten „TestDataY“ und „TestDataX“ anhand eines Bayesschen linearen Regressionsmodells, basierend auf den Trainingsdaten „TrainDataY“ und „TrainDataX“.
Bei Auswahl von „UseLogForY“ = 1 (standardmässig = 0) werden die Daten aus „TrainDataY“ logarithmiert in die Berechnung übernommen. Mittels „UseRepeatedMedianRegression“ geben Sie, ob der Kleinst-Quadrate Schätzer (standardmässig = 0) oder die absoluten Abweichungen (bei „UseRepeatedMedianRegression“ = 1) anhand des Median (0.5 Quantil) Schätzers angewandt wird. Mit „kfolds“ (standardmässig = 1) geben Sie an, wie viele unabhängige Stichproben aus der Datenmenge „DataY“ und „DataX“ (paarweise) gewählt werden, um die Stichprobenvariabilität einzugrenzen. Info: Im Fall, dass DataX mehrere Spalten umfasst (multiple, lineare Regression) wird der Kleinst-Quadrate Schätzer genommen.
Bemerkung: Zur Bestimmung der „a-priori“ Verteilung der Regressionsparameter (etwa Steigung, Achsenabschnitt) wird anhand einer Stichprobe von „DataY“ und „DataX“ (paarweise) eine Kerndichteschätzung vorgenommen, um das Regressionsmodell zu stabilisieren. Die Likelihood und deren Verteilung wird anhand des Bootstrap-Verfahrens hergeleitet und mittels Kerndichteschätzer aufbereitet.
fmc_BayesClassifier(FeatureData, ClassData, PredictData, Testproportion, ModelSelection, ReturnConfusionMatrixTestSet, ReturnPredictionInterval, PredictionInterval, Iterations, HisBins, LowerLimit, UpperLimit, FeatureImpact, FeatureDescription, kfolds, UseFlatPrior, UseWeightedFeatures)
Führt eine Klassifikation von Daten anhand des Satzes von Bayes durch. Ausgangslage bilden vorab klassifizierte Daten (ClassData) dar, welche anhand der Merkmale aus FeatureData beschrieben werden. Die neu zu klassifizierenden Daten liegen in PredictData vor. Die FeatureData werden anhand von Testproportion in eine Trainings- und in eine Testmenge unterteilt. Über Modelselection kann der Klassifikator weiter spezifiziert werden, wobei zwischen dem Norrmal/Bernoulli Klassifikator, der empirischen Verteilung – ermittelt anhand Kerndichteschätzer – oder einer automatischen Auswahl unterschieden wird. Falls ReturnConfusionMatrixTestSet mit WAHR angegeben wird, erfolgt als Ausgabe eine Wahrheitsmatrix in Bezug auf die Testdaten. Bei Angabe von FALSCH werden die PredictData anhand des gesamten Datensatzes (Trainings -und Testmenge) klassifiziert. Falls ReturnPredictionInterval mit WAHR angegeben wird, wird statt einer Punktprognose das glaubhafte Intervall bei PredictionInterval ausgegeben. Alternativ kann auch der Einfluss der erklärenden Variablen auf die Klassifizierung anhand der Testdaten ausgegeben werden (FeatureImpact = WAHR). Für die erklärenden Variablen kann die Bezeichnung aus FeatureDescription übernommen werden, andernfalls wir die Bezeichung „Variable_“ vorangestellt.
Mittels Iterations werden die Anzahl Stichproben aus der jeweiligen Verteilung bestimmt, HisBIns, LowerLimit und UpperLimit spezifizieren detaillierter den Kerndichteschätzer. kfolds legt die Anzahl Versuche fest, welche bei ReturnConfusionMatrixTestSet = WAHR angewandt wird. Mit UseFlatPrior (WAHR, Standard = FALSCH) legen Sie fest, ob ein Non-informative Prior als Basis herangezogen werden soll. Das ist dann anzuraten, wenn Sie wissen, dass die Stichprobe verzerrt ist. Mit UseWeightedFeatures (WAHR, Standard = FALSCH) fliessen die einzelnen Merkmale gewichtet in die Klassifikation ein.
Eine vertiefendes Beispiel finden Sie im Beispiel "Breastcancer_Simulation_Classification.xlsx"
KLassische, lineare Regression
fMC_RegressionX(Name1, Name2, Referenz)
Bestimmt die Steigung der Regression zweier Variablen. Name1 ist x-Vektor, Name2 ist y-Vektor, dies bezugnehmend auf die Variante "Referenz".
fMC_RegressionY(Name1, Name2, Referenz)
Bestimmt den Achsenabschnitt der Regression zweier Variablen. Name1 ist x-Vektor, Name2 ist y-Vektor, dies bezugnehmend auf die Variante "Referenz".
fMC_BootStrapVectorLinearRegressionX(DataY,DataX,NumberNewSamples, UseRepeatedMedianRegression)
Bestimmt die Steigung eines linearen Regressionsmodells für die abhängige Variable „DataY“ und der unabhängigen Variablen „DataX“ mittels Bootstrapping, wobei „NumberNewSamples“ die Anzahl der neuen Stichproben angibt. Resultat ist eine Matrix mit der Dimension „NumberNewSamples“ x 1.
Falls «UseRepeatedMedianRegression» = 1 wird statt einer linearen Kleinstquadrateschätzung eine Regression auf Basis des 50%-Perzentils vorgenommen, bei der die absoluten Abweichungen und nicht die quadratischen Abweichungen minimiert werden. Info: «UseRepeatedMedianRegression» wird nur bei einer abhängigen Variablen von DataX beigezogen, andernfalls wir der Kleinst-Quadrate Schätzer genommen.
fMC_BootStrapVectorLinearRegressionY(DataY,DataX,NumberNewSamples, UseRepeatedMedianRegression)
Bestimmt den Achsenabschnitt eines einfaches linearen Regressionsmodells für die abhängige Variable „DataY“ und der unabhängigen Variablen „DataX“ mittels Bootstrapping, wobei „NumberNewSamples“ die Anzahl der neuen Stichproben angibt. Resultat ist eine Matrix mit der Dimension „NumberNewSamples“ x 1.
Falls «UseRepeatedMedianRegression» = 1 wird statt einer linearen Kleinstquadrateschätzung eine Regression auf Basis des 50%-Perzentils vorgenommen, bei der die absoluten Abweichungen und nicht die quadratischen Abweichungen minimiert werden. Info: «UseRepeatedMedianRegression» wird nur bei einer abhängigen Variablen von DataX beigezogen, andernfalls wir der Kleinst-Quadrate Schätzer genommen.
fMC_BootStrapVectorLinearRegressionRE(DataY,DataX,NumberNewSamples, UseRepeatedMedianRegression)
Bestimmt den Regressionsfehler (Standardfehler) eines einfaches linearen Regressionsmodells für die abhängige Variable „DataY“ und der unabhängigen Variablen „DataY“ mittels Bootstrapping, wobei „NumberNewSamples“ die Anzahl der neuen Stichproben angibt. Resultat ist eine Matrix mit der Dimension „NumberNewSamples“ x 1.
Falls «UseRepeatedMedianRegression» = 1 wird statt einer linearen Kleinstquadrateschätzung eine Regression auf Basis des 50%-Perzentils vorgenommen, bei der die absoluten Abweichungen und nicht die quadratischen Abweichungen minimiert werden. Info: «UseRepeatedMedianRegression» wird nur bei einer abhängigen Variablen von DataX beigezogen, andernfalls wir der Kleinst-Quadrate Schätzer genommen.
fMC_BootStrapVectorMLRegression(DataY,DataX,NumberNewSamples, UseRepeatedMedianRegression)
Bestimmt die möglichen Parameterausprägungen eines multiplen, linearen Regressionsmodells für die abhängige Variable „DataY“ und der unabhängigen Variablen „DataX“ mittels Resampling, wobei der erste Parameter dem Achsenabschschnitt und der letzte Parameter dem Standardfehler der Regression entspricht. Ausgabe ist eine n x m Matrix, wobei m der Anzahl der Stichprobenmenge entspricht.
fMC_BootStrapVectorMLRegressionParameters(DataY,DataX,NumberNewSamples, UseRepeatedMedianRegression,CI,FeatureDescription)
Bestimmt die möglichen Parameterwerte eines multiplen, linearen Regressionsmodells für die abhängige Variable „DataY“ und der unabhängigen Variablen „DataX“ mittels Resampling, wobei der erste Parameter dem Achsenabschschnitt und der letzte Parameter dem Standardfehler der Regression entspricht. Mit „CI“ geben Sie das Intervall der resultierenden Verteilung an, wobei die Anzahl „NumberNewSamples“ zur Generierung der Prognoseverteilung herangezogen wird. „FeatureDescription“ geben die Bezeichnungen von „DataX“ an. Resultat ist eine (m + 2) x 4 Matrix, wobei m die Anzahl der unabhängigen Variablen umfasst, zuzüglich einer Zeile für den Schnittpunkt und eine Zeile für den Regressionsfehler der Regressionsgleichung.
fMC_PredictiveRegressionLine(Name1, Name2, Value, Percentile, Referenz)
Bestimmt den typischen Wert des linearen Regressionsmodells am Wert «Value» anhand des Steigungsparameters «Name1» und des Achsenabschnitt «Name2», dies bezugnehmend auf die Variante "Referenz", wobei «Percentile» den entsprechenden Perzentilwert der typischen Prognoseverteilung angibt. Ist Percentile mit 0 angegeben (standardmässig) wird der Erwartungswert des typischen Wertes ausgegeben.
fMC_PredictiveRegressionLineValue(Name1, Name2, Name3, Value, Percentile, Referenz)
Bestimmt den Prognosewert der Regressionsgeraden am Wert «Value» anhand des Steigungsparameters «Name1», des Achsenabschnitt «Name2» und des Schätzfehlers «Name3», dies bezugnehmend auf die Variante "Referenz", wobei «Percentile» den entsprechenden Perzentilwert der Prognoseverteilung angibt. Ist Percentile mit 0 angegeben (standardmässig) wird der Erwartungswert ausgegeben. Dieser entspricht bei symmetrischem Schätzfehler dem Erwartungswert des typischen Wertes
SONSTIGES
fMC_ADs(Name1, Referenz)
Führt einen Anderson-Darling Test auf Normalverteilung der unter «Name» selektierten Variablen durch, dies bezugnehmend auf die Variante "Referenz". Gibt «Wahr» zurück, falls die Daten sehr wahrscheinlich normalverteilt sind.
fMC_Iterations()
Gibt die Anzahl der Iterationen wieder.
fMC_GetInputName(Pos)
Gibt den Namen der Inputvariable an Position «Pos» zurück
fMC_GetUserDefinedInputName(Pos)
Gibt den Namen der benutzerdefinierte Inputvariable an Position «Pos» zurück
fMC_GetOutputName(Pos)
Gibt den Namen der Outputvariable an Position «Pos» zurück.
fMC_Bin(Optional Value)
Legt die Anzahl der Säulen eines Histogramms über ‘Value’ fest (global gültig). Sobald Value festgelegt ist, werden alle Histogramme und interne Funktionen, welche die Anzahl Säulen eines Histogramms als Input aufnehmen, anhand Value aufbereitet.
fMC_SimulaOn(Optional Value)
Arbeitsmappe-Simulationsmodus: Bestimmt, ob zufällige Werte (WAHR) oder der Erwartungswert der Verteilungsfunktion (FALSCH) nach Neuberechnung des Tabellenblattes/Arbeitsmappe ausgegeben werden sollen. Beachten Sie, dass die Auswertung der Simulationsergebnisse («Starten») nur mit dem Wert FALSCH erfolgen kann.
fMC_NBT(Matrix1, UseSummary)
Prüft anhand des Chi-Quadrat-Test, ob Daten Newcomb-Benford verteilt sind. Ausgabe ist eine 18x3 Matrix, wobei die ersten 9 Zeilen die Häufigkeiten der Zahlen 1 bis 9 wiedergeben (Spalte 1 = gemessen; Spalte 2 = Newcomb-Benford-Verteilung).
Siehe auch hier.
fMC_LDT(Matrix1, UseSummary)
Prüft anhand des Chi-Quadrat-Test, ob die letzte Zahl vor dem Dezimaltrennzeichen gleichverteilt ist. Ausgabe ist eine 19x3 Matrix, wobei die ersten 10 Zeilen die Häufigkeiten der Zahlen 0 bis 9 wiedergeben (Spalte 1 = gemessen; Spalte 2 = Gleichverteilung).
Siehe auch hier.
fMC_Best(Value)
Gibt das definierte Konfidenzniveau des «best» case wieder. Falls Value >= 0 und Value <=1, wird der «best» case dynamisch anhand von Value ermittelt.
fMC_Real(Value)
Gibt das definierte Konfidenzniveau des «real» case wieder. Falls Value >= 0 und Value <=1, wird der «real» case dynamisch anhand von Value ermittelt.
fMC_Worst(Value)
Gibt das definierte Konfidenzniveau des «worst» case wieder. Falls Value >= 0 und Value <=1, wird der «worst» case dynamisch anhand von Value ermittelt.
fMC_Name(MCFLO_Name)
Gibt den Namen der MC FLO Variable aus der angegebenen Zelle der gleichen Arbeitsmappe aus; kann auch in Kombination mit anderen Funktionen genutzt werden; etwa fMC_Min(fMC_Name(«Name»)). Beachten Sie aber, dass fmc_Name nur einmal pro Formel verwendet wird.