
Viele Unternehmen vergeben finanzielle Mittel für die Lancierung von Projekten nach Phasen. Etwa unterteilt nach Studie, Konzept und Ausführung. Und immer wieder kommt es auch vor, dass diese Mittel gestreckt werden müssen, um die laufende Phase abschliessen zu können. Die Mittel binden Ressourcen und können zu Liquiditätsengpässen führen. Daher ist es unabdingbar, dass Projektmehrbedarfe frühzeitig identifiziert werden.
Vorab: Eine Kausalanalyse zu Identifizierung der wahren Ursachen ist unverzichtbar, liefert häufig aber nicht eine schnelle Antwort, womit Klassifikationen, welche Voraussagen treffen, kurzfristig die bessere Alternative darstellen.
Klassifikationen versuchen anhand von Merkmalen eine Voraussage über ein zukünftiges Ereignis zu treffen. Dabei wird untersucht, welche Kombinationen von Merkmalen in der Vergangenheit zu welchen Ereignissen geführt haben.
Im hier betrachteten Fall geht es um die Frage, ob zusätzliche finanzielle Mittel für Projekte bereitgestellt werden müssen, etwa weil die Merkmale ähnlich derjenigen Projekte sind, für welche in der Vergangenheit zusätzliche Mittel ausgesprochen wurden.
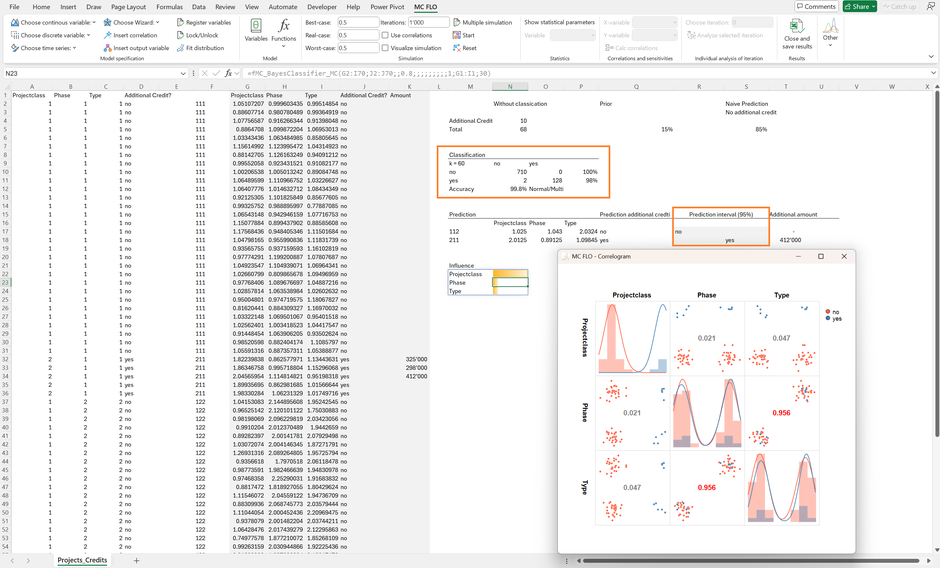
Für unser fiktives Unternehmen liegen Daten für Phasenfreigaben differenziert nach Projektklasse (etwa Bauprojekt, IT-Projekt), der Phase (etwa Studie), dem Typ (etwa Einzelprojekt, Gemeinschaftsprojekt) und Informationen zu Mittelstreckungen vor (ja, nein). Falls zusätzliche Mittel für eine Projektphase – gegeben die Merkmale – ausgesprochen wurden, sind die Mehrbedarfe zusätzlich ausgewiesen.
Insgesamt liegen 68 Phasenanträge mit den Angaben zu Mittelstreckungen vor. In 10 von den vorhandenen 68 Phasenanträgen wurde ein Mehrbedarf festgestellt (15%).
Die naive Vorgehensweise zur Sicherstellung der Liquidität der Projekte über einen Puffer, welcher sich aus der Multiplikation der Wahrscheinlichkeit der Mehrbedarfe mit dem durchschnittlichen Mittelmehrbedarf ergibt, greift zu kurz und führt zu Fehlallokationen der finanziellen Mittel. Entweder die beantragte Phase wird keinen Mehrbedarf anmelden, oder der Mehrbedarf ist grösser als der Puffer.
Methoden des maschinellen Lernens – hier mittels eines Bayesschen Modells – können bessere Prognosen liefern und helfen dabei, die finanziellen Mittel besser zu allokieren.
Wir haben die Daten in eine Trainings-/ und Testmenge unterteilt (80/20). Anhand der Trainingsmenge wird das Modell kalibriert. Mit dem kalibrierten Modell werden die Testdaten verprobt. So zeigt sich, dass das Modell eine Erfolgsquote von 99,8% bei 60-facher Wiederholung der Aufteilung Trainings-/Testmenge aufweist. Von den 710 effektiv ohne Mehrbedarf erteilten Phasenanträge wurden vom Modell alle als solche identifiziert. Von den 130 Phasenanträgen, welche effektiv einen Mehrbedarf anmeldeten, wurden nur 2 nicht korrekt identifiziert. Das Modell ist somit besser als raten oder bei Anwendung der einfachen Strategie «immer keinen Mehrbedarf voraussagen». Im letzteren Fall wäre die Erfolgsquote 85%.
Für einen neuen Phasenantrag mit der Kombination «112» (es soll beachtet werden, dass diese Kombination bisher nicht in den Daten vorhanden ist) soll nun eine Vorhersage getroffen werden.
Das Modell geht davon aus, dass kein Mehrbedarf angemeldet wird. Doch wie sicher können wir uns sein? Da das Modell die Bayessche Statistik nutzt, können glaubhafte Intervalle ausgegeben werden. Im 95% Bereich («wir sind uns zu 95% sicher») ist immer noch davon auszugehen, dass kein Mehrbedarf ersichtlich wird.
Bei der Kombination «221» trifft der Algorithmus die Vorhersage, dass ein Mehrbedarf notwendig sein wird, dies mit 95%-Sicherheit. Der maximale Mehrbedarf wird in diesem Fall - anhand der gemessenen Daten - bei ca. 412 TCHF liegen.
Bei der Ursachenforschung ist anhand einer Feature-Impact Analyse der Zeitaufwand reduziert, da das Modell dem Merkmal «Projektklasse» (etwa «IT-Projekt») die höchste Erklärungskraft attestiert.
Fazit: Klassifikationen als Teil des Machine Learnings, welches wiederrum als Teil der (schwachen) KI eingestuft sind, können auch in Microsoft Excel in Kombination mit MC FLO rasch und mit nur einer Formel umgesetzt werden und zu einer erhöhten Effizienz bei der Allokation der Projektmittel bei Phasenanträgen beitragen. Durch Angaben zu Prognosegrenzen wird die im Modell berücksichtigte Unsicherheit transparent, was bessere Entscheidungen begünstigt.
*Info: Wir haben alle Merkmale – welche als Text vorliegen (etwa «Studie») - in Kategorien, diese in Nominalwerte (etwa 1, 2) und schliesslich in eine Normalverteilung überführt. Dies erleichtert die visuelle Darstellung. Wir haben das Modell mit der Memory Calculation Engine aufbereitet.
Kommentar schreiben